Automatisering Avansert
Infrastruktur oversikt
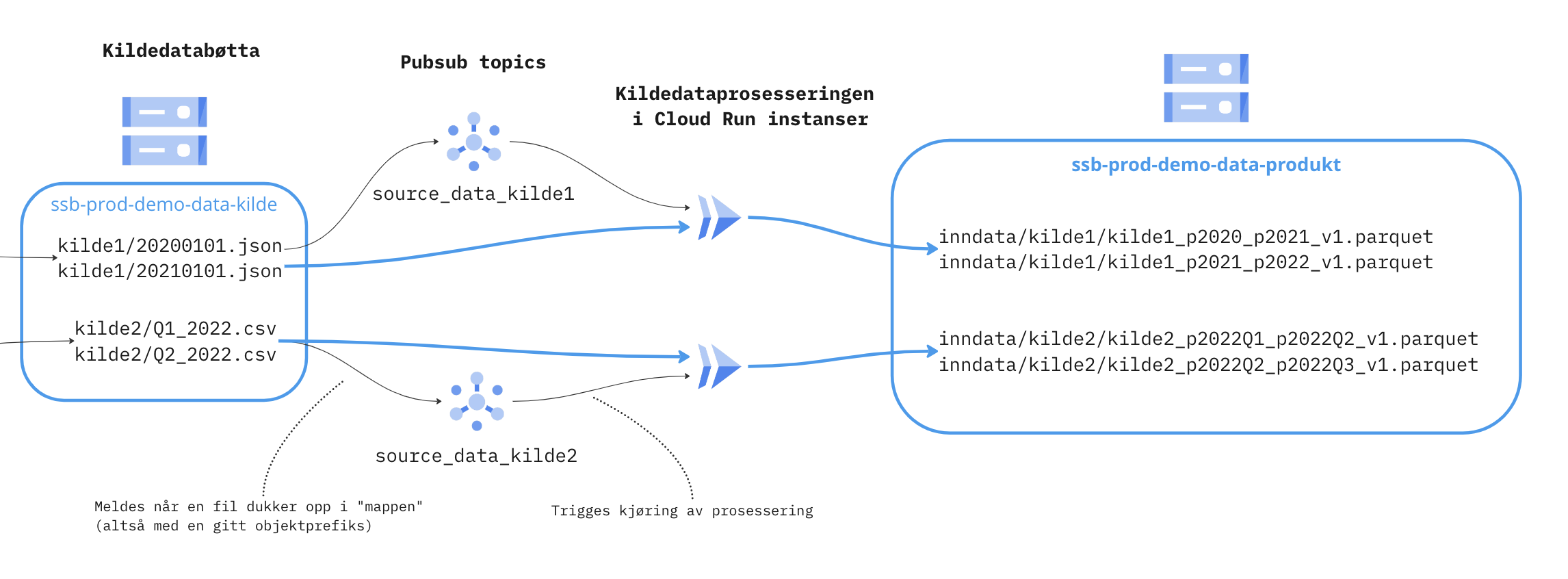
Ressurser
Som utgangspunkt, får hver prosesseringsinstans standard ressurstildeling for Cloud Run, dvs. 1 CPU kjerne og 512MB minne. Dette kan være for lite i noen tilfeller, særlig for større kildedatafiler. Det er mulig å konfigurere dette vha. config.yaml.
Mulige verdier
Man setter en verdi memory_size i config.yaml til en integer mellom 0 og 32 (GiB). Bak kulissene konfigurerer det også antall CPU kjerner i henhold til begrensningene som Google setter. Fasiten for de presise verdiene som blir satt finnes her.
Eksempel config.yaml
Tatt fra rundstykker eksempelet, hvis man hadde behov for 10GiB minne, kunne man konfigurere det slikt:
folder_prefix: rundstykker
memory_size: 10 # GiBUtrulling
Endringer i config.yaml krever at man skriver atlantis apply i en PR for å effektuere endringene.
Tilgjengelige pakker
En liste over Python pakker man kan benytte seg av i process_source_data.py finnes her. Ta gjerne kontakt med Dapla Kundeservice hvis man har behov for ytterligere.
Skalering
Hver kilde kan skalere opp med parallele prosesseringsinstanser. Det gjør det kjappere å prosessere mange filer. I utgangspunktet er dette begrenset til 5 parallele instanser, men det kan økes ved behov.
Testing i staging-miljø
Å benytte både prod og staging miljøer er en god praksis for å sikre at nye funksjoner og endringer fungerer som forventet før de rulles ut i produksjon. Staging-miljøet gir mulighet til å validere endringer i en mer kontrollert og isolert setting før de blir lansert i produksjonsmiljøet med skarpe data.
Automatiseringsløsningen støtter oppsett av kilder i både staging og prod miljø. For oppsett av kilder i staging-miljøet, må man legge til kilden i en egen undermappe kalt staging. Dette kan gjøres på samme måte som beskrevet her, bortsett fra at kilden legges i en undermappe som heter staging.
Her er et eksempel på konfigurasjon av både staging og produksjonsmiljø:
...
├── automation
│ └── source_data
│ ├── prod
│ │ └── kilde1
│ │ ├── config.yaml
│ │ └── process_source_data.py
│ └── staging
│ └── kilde1
│ ├── config.yaml
│ └── process_source_data.py
...Innholdet i config.yaml for både staging og produksjonsmiljø er som hovedregel identisk, men bøttene som benyttes vil være forskjellige. Stagingmiljøet har en egen kildedatabøtte kalt gs://ssb-staging-my-project-data-kilde.
Validering
For å gi raskt tilbakemelding på noen mulige feilsituasjoner, så kjøres det enkel validering på kilde config og process_source_data.py når en PR er opprettet.
Hvis valideringen feiler, så må feilen rettes før PRen merges.
Testene feiler hvis:
- Kildemappen ikke har et python script kalt process_source_data.py med metodesignaturen, som beskrevet her.
- Kildemappen ikke har en yaml fil og en gyldig folder_prefix definert, som i dette eksempelet.
- Python scriptet ikke kan importeres av tjenesten. Tjenesten støtter kun disse tredjeparts pakkene.
- Hvis Pyflakes finner feil med kildens Python script.
Validerings logger
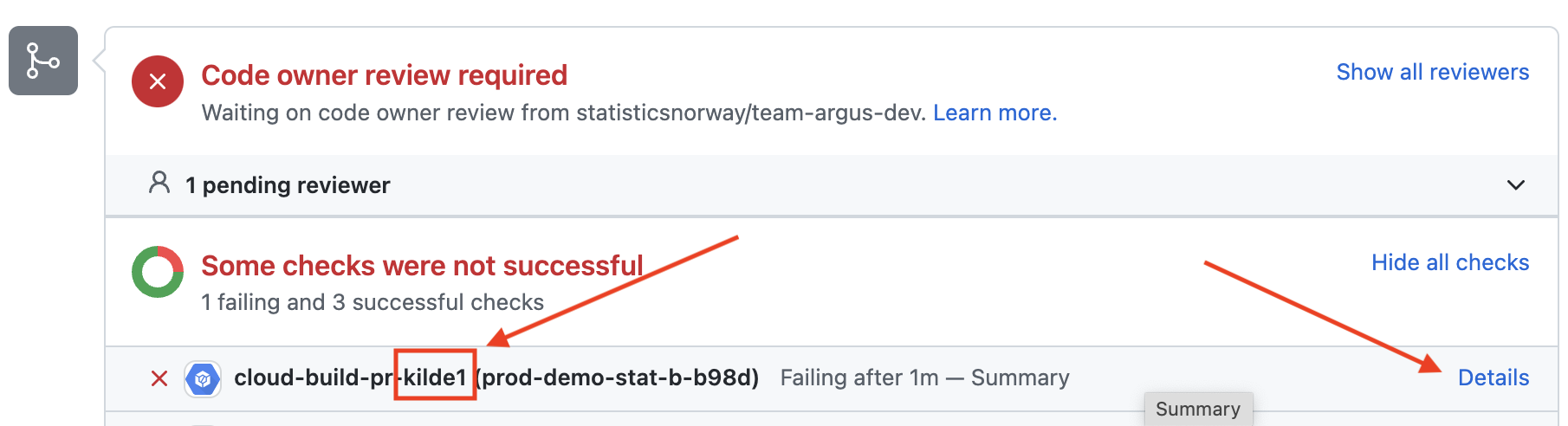
Hvis validerings testene feiler kan det være nyttig å se på loggene for å finne frem til feilen.
- Finn frem til testen som feiler, i bildet feiler valideringstestene for kilde1. Trykk så på lenken “Details” som vist i bilde under.
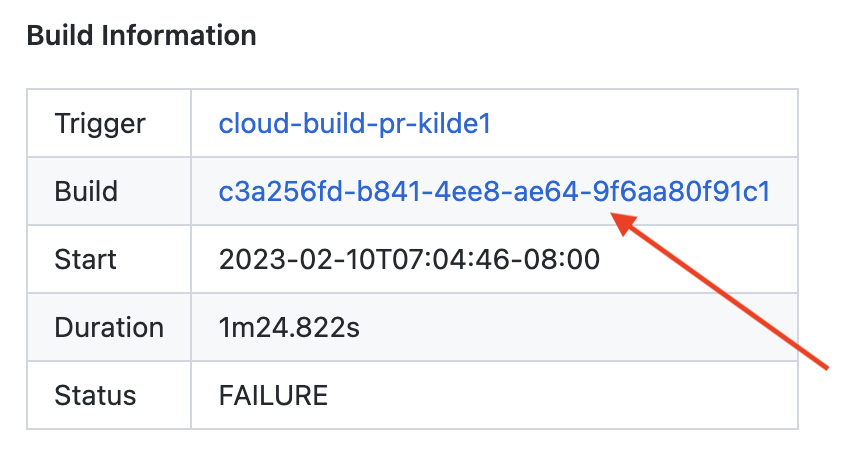
- På siden du nå har kommet til skal det være en tabell som heter “Build Information”, trykk på lenken i Build kolonnen.
- Du har nå kommet frem til loggene, se etter indikasjoner på feil. I eksemplet under ser vi at testen test_main_accepts_expected_number_of_args feiler fordi
process_source_data.pymangler en main funksjon.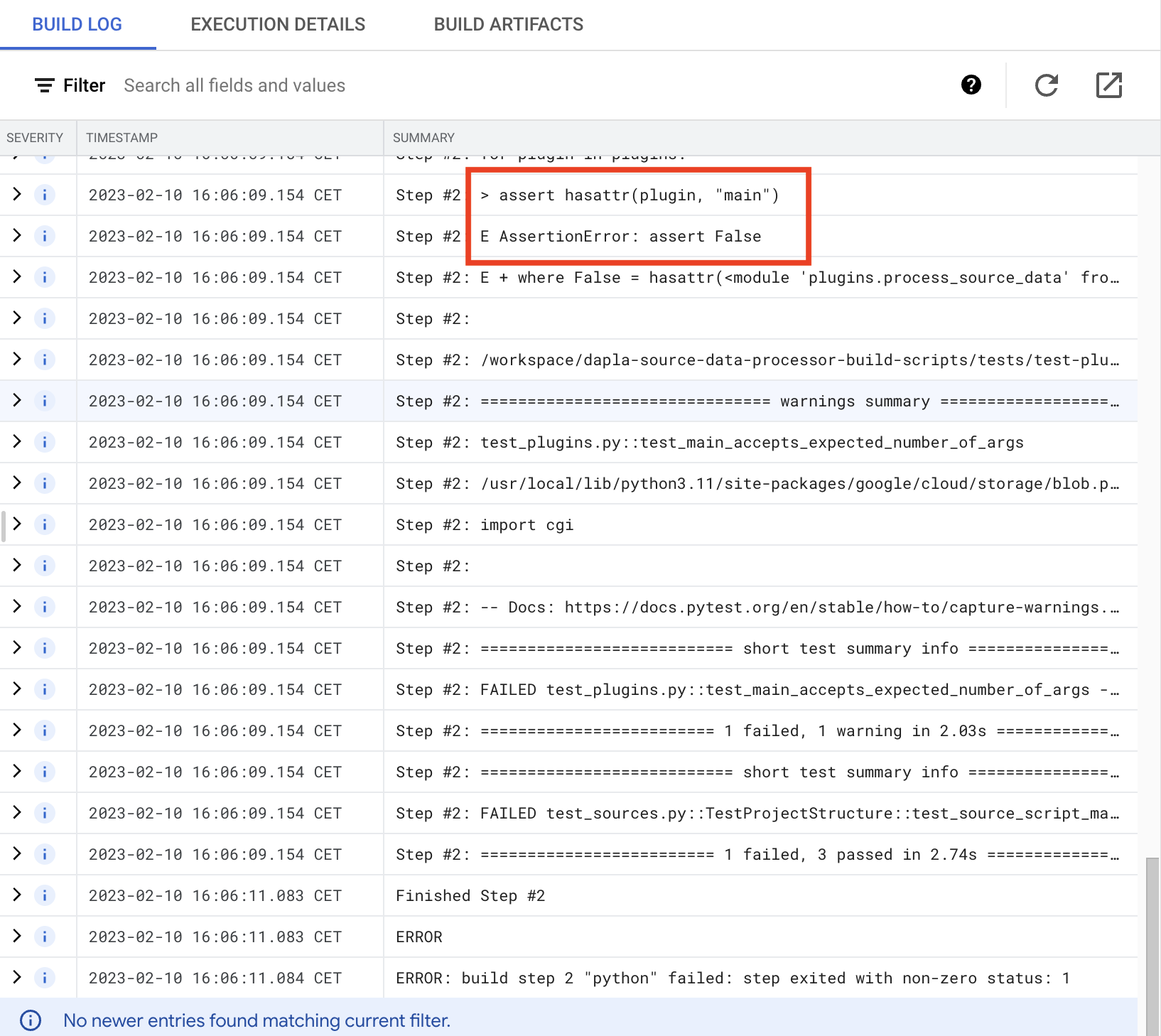
- Fiks feilen og push endingen til samme branch, testen vil da starte på nytt.
Utrulling
Endringer til process_source_data.py blir automatisk rullet ut når en PR er merget til main branchen. Utrullingsprosessen tar noe tid, ca. 2-3 minutter fra branchen er merget til tjenesten er oppdatert, for å bekrefte at tjenesten er rullet ut kan du følge stegene i neste avsnitt.
Bekrefte utrulling
Stegene under viser hvordan man går frem for å finne resultat av utrullingen av kilden “ledstill” for teamet “arbmark-skjema”. Og forutsetter at koden er pushet til main branchen.
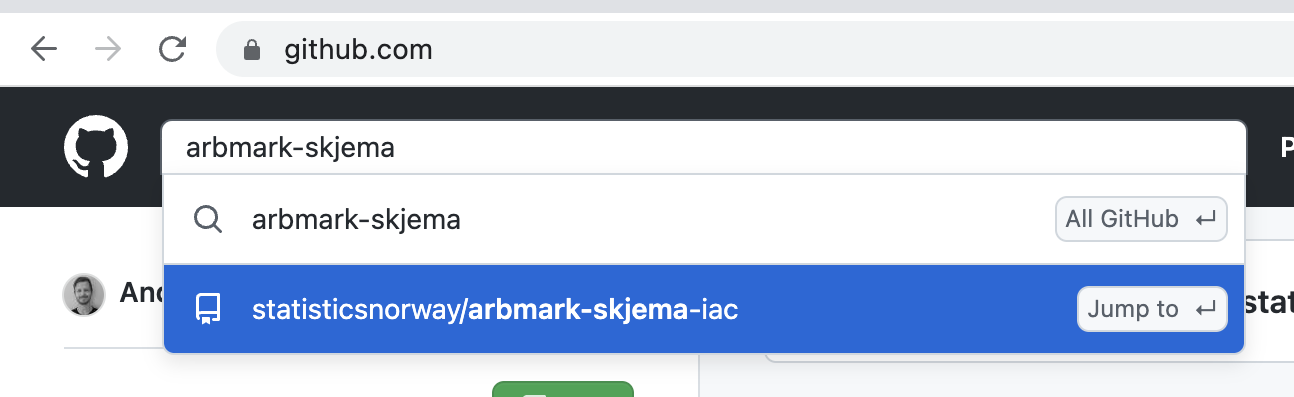
- Naviger til GitHub.
- I søkefeltet oppe i venstre hjørne skriv arbmark-skjema og klikk “Jump to” arbmark-skjema-iac. Som i bilde under.
- Når utrullingen er ferdig vil en av disse ikonene vises, grønn hake betyr at tjeneste er rullet ut med koden som ligger i main og at nye filer blir behandlet med koden som ligger der.
 . Rødt kryss indikerer at utrullig har feilet.
. Rødt kryss indikerer at utrullig har feilet. 
Se etter symbolene der hvor den røde pilen i bilde under peker. I eksempel er utrulligen vellykket.
Monitorering av tjenesten
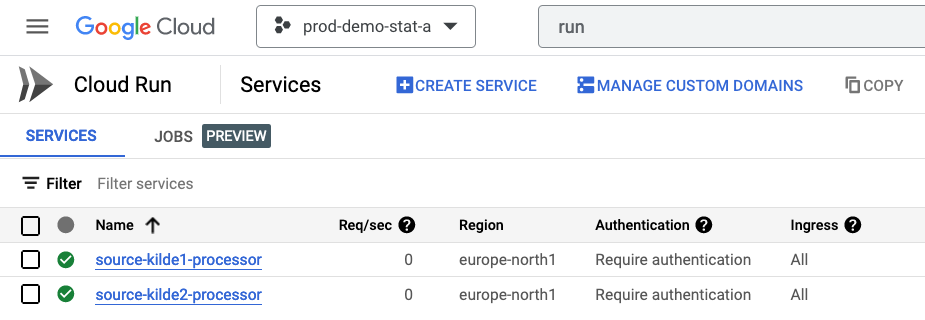
Man får en oversikt over kildene man har konfigurert prosessering for og statusen på dem ved hjelp av konsollet på GCP. Der navigerer man til siden for Cloud Run (se Figur 2) som er kjøremiljøet som kildedata prosessering benyttes av. Eksempel URl er: https://console.cloud.google.com/run?project=<teamets-prosjekt-id>
Her får man en oversikt av ressursbruk og loggene til prosesseringen.
Logger
Etter du har valgt kilden kan du se logger ved å velge fanen “LOGS”. Her ligger alle logger for den spesifikke kilden. For å få bedre oversikt over eventulle feil kan man sette severity til error. Dette vil uten ekstra konfigurasjon gi oversikt over alle uhåndterte exceptions. 
Ubehandlede filer
Hvis en fil blir mottatt av tjenesten, men ikke lar seg behandle blir det skrevet til loggen. Man kan få en oversik over hvilke filer som ikke har blitt prosessert ved å søke etter: Could not process object. 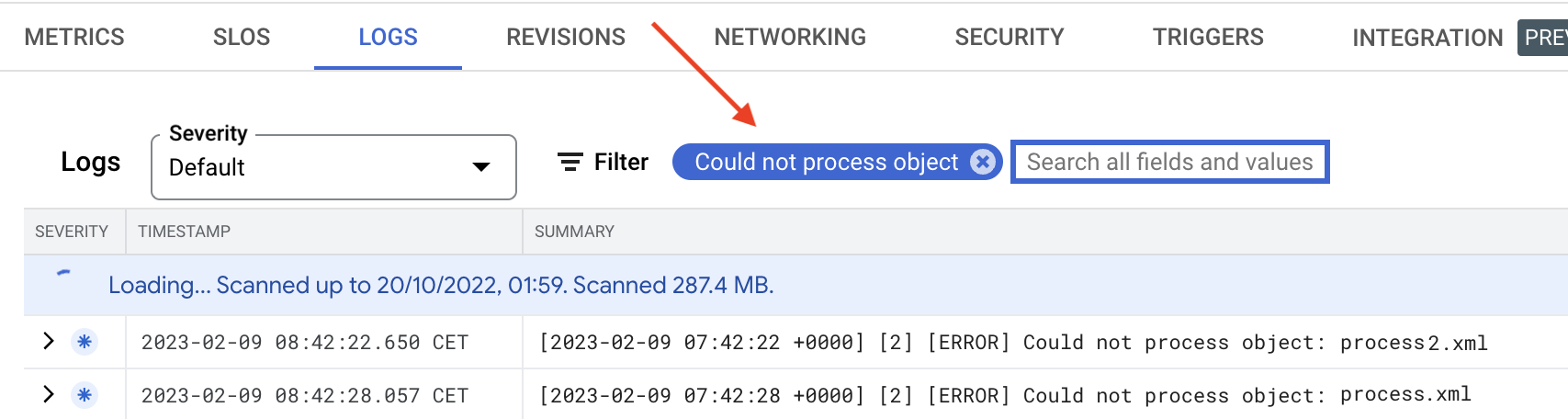
Trigge tjenesten manuelt
Noen ganger vil det være nødvendig å trigge kjøring av en kilde uten at de tilhørende filene i kildebøtta er oppdatert f.eks. etter en endring i prosseseringsskriptet. For å gjøre dette kan man benytte seg av dapla toolbelt.
For å trigge en ny kjøring må man være data-admin i teamet og ha denne informasjonen tilgjengelig:
- project_id(prosjekt id) for kilden, den finner man ved å følge beskrivelsen her.
- folder_prefix beskriver stien til filene som skal behandles og fungerer på samme måte som i config.yaml
- source_name finner man ved å se på navnet til mappen hvor kilden konfigureres, i eksempelet her ser vi at team
smaabaksthar to kilderbollerogrundstykker.
Eksempel
Dette eksemplet viser hvordan man går frem for å manuelt trigge kilden boller for team smaabakst.
Team smaabakst ønsker å re-prosessere alle filer i kilden boller. Ved å bruke samme folder_prefix som i config.yaml vil alle filer som tilhører kilden bli prosessert på nytt.
from dapla import trigger_source_data_processing
project_id = "prod-smaabakst-b69d"
source_name = "boller"
folder_prefix = "boller"
trigger_source_data_processing(project_id, source_name, folder_prefix)