Navngiving av mapper og datasett (filer)
Navnestandarden3 baseres på kapitelet “Bøtter” i Dapla- manualen, interndokumentet Datatilstander i SSB og “statistikk kortnavn” i Statistikkregisteret.
3 Navnestandarden er foreløpig begrenset til lagring av datafiler i Google Cloud Storage Buckets - ofte kalt “bøtte(r)” i SSB. Navnestandard for bruk av andre typer datalagringsteknologier i Google Cloud, f.eks. BigQuery og CloudSQL, dekkes ikke av denne navnestandarden!
Mapper (kataloger)
Standard lagringsområder (bøtter) som opprettes for alle statistikkprodukt-team i SSB
Følgende lagringsområder (bøtter) operettes for alle team:
- ssb-prod-<teamnavn>-data-kilde : Inneholder ubehandlede rådata fra datakildene.
- ssb-prod-<teamnavn>-data-produkt : Inneholder data knyttet til statistikkproduktet.
- ssb-prod-<teamnavn>-data-delt : Inneholder data knyttet til statistikkproduktet som kan deles med andre statistikkteam.
Denne navnestandarden gjelder primært for lagringsområdene data-produkt og data-delt, men er også anbefalt brukt for data-kilde*.
Datatilstander, prosesser, permanente data og temporære data
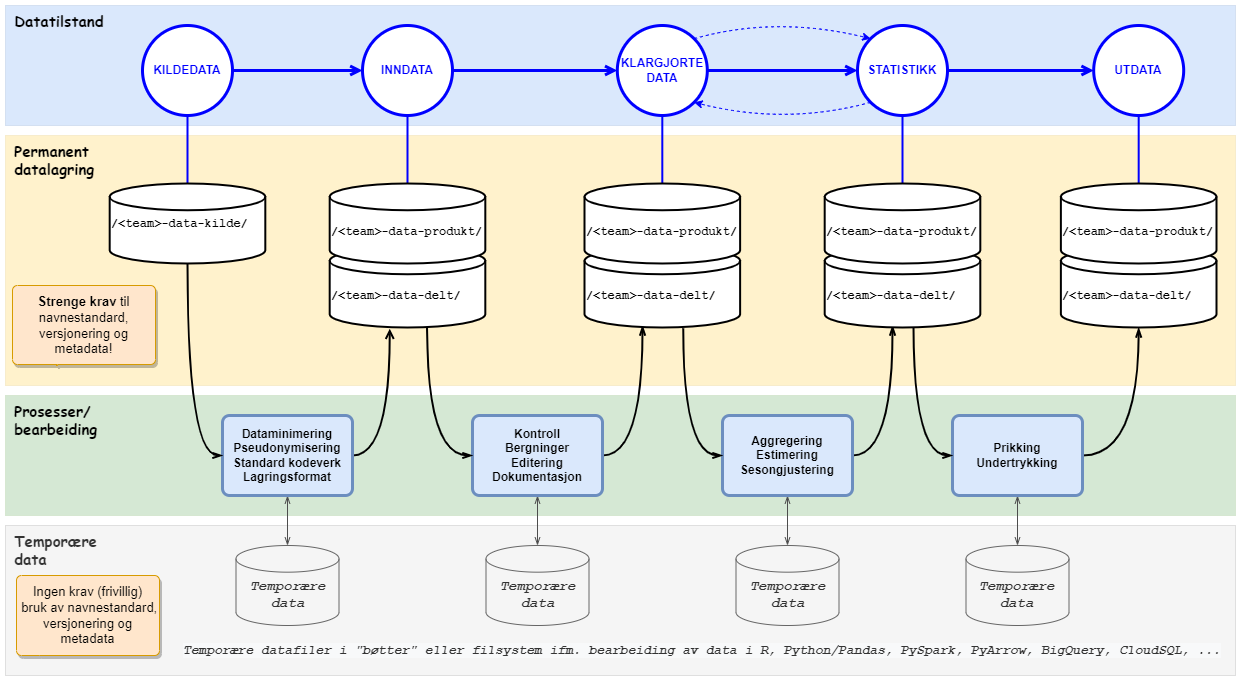
I en statistikkproduksjon skal det for hver datatilstand lagres permanente datasett (datafiler). Disse datasettene skal følge denne navnestandarden inkludert kravet til versjonering og dokumentasjon (metadata). Det er imidlertid viktig å skille mellom behovet for permanente data og temporære data. I prosessene som kjøres mellom hver datatilstand, f.eks. klargjøringsprosessene mellom inndata og klargjorte data, vil det være behov for temporær datalagring. Temporære data skal aldri deles, og det stilles derfor ingen krav til verken navnestandard, versjonering eller dokumentasjon (metadata) av disse. Det er helt opp til hvert produkt-team hvordan de vil organisere temporære data. Ved å skille mellom permanent datalagring og temporære datalagring oppnår vi en optimal løsning både for dataprodusenter (statistikkseksjonene) og data-konsumentene (interne og eksterne brukere). Produsentene får nødvendig fleksibilitet til å prosessere data i temporære områder, mens konsumentene får godt dokumenterte og versjonerte data i en standardisert mappe-struktur og tilgjengelig for gjenfinning i en søkbar datakatalog.
Statistikkprodukter og dataprodukter
Statistikkprodukter
Alle SSBs tidligere og nåværende statistikkprodukter inngår Statistikkregisteret. Før publisering på ssb.no må alle statistikkprodukter være registrert i Statistikkregisteret med informasjon om bl.a. statistikkens navn, emne-område, eierseksjon og publiseringstidspunkt. I tillegg får statistikkene tildelt et kortnavn. Eksempler på statistikk-kortnavn er:
"kpi"for konsumprisindeksen"reise"for reiseundersøkelsen"ftot"for næringslivstjenester, omsetning etter tjenestetype
Kortnavnene er unike og stabilt over tid (uforanderlige). De er derfor valgt som grunnlag for kategorisering/inndeling av datasett i Dapla, dvs. benyttes som grunnlag for navn på mappene i lagringsområdene (bøttene).
Statistikkregisteret har også et API for å hente informasjon om alle SSBs statistikker i json- format.
Dataprodukter
Det er imidlertid ikke slik at alle data i SSB kan knyttes direkte til en statistikk i Statistikkregisteret. Flere statistikkseksjoner i SSB bearbeider også data til andre bruksområder og formål, eksempelvis klargjøring av data til forskning og utlån, bearbeiding av data som skal inngå som en del av andre statistikker, og data som inngår i populasjonsregistre. Denne typen data omtales i dette dokumentet som “dataprodukter”, og i navnestandarden skiller vi mellom “dataprodukter” og “statistikkprodukter”. Det eksisterer ikke et register med “kortnavn” for data-produktene i SSB, men hvert team må lage kortnavn også for dataproduktene. Eksempler på dataprodukt-kortnavn er “nudb” (utdanningsdatabasen) og “fd_trygd” (forløpsdatabasen for trygdedata).
For å skille mellom dataprodukter og statistikkprodukter skal navnet på alle mapper som representerer dataprodukter ha endelsen “_data”, f.eks. “nudb_data” og “fd_trygd_data”.
Mappestruktur for organisering av datasett i Dapla-teamenes lagringsområder (bøtter)
Med utgangspunkt i standard bøtter som opprettes for alle statistikk-team i DAPLA, Statistikkregisteret og datatilstander, er det utarbeidet følgende regler for mappestrukturen og navngiving av mappene i bøttene (gjelder for data-produkt-bøtte og data-delt-bøtte, men anbefalt også for data-kilde- bøtte) :
ssb-prod-<team-name>-data-produkt/
└─ <statistikk-kortnavn> | <dataprodukt>_data/
└── <datatilstand>/
├── [datasett-1]
├── [datasett-2]
└── [datasett-NN]- Første nivå er lagringsområdet (bøtte)
- Andre nivå er:
-> enten kortnavn fra Statistikkregisteret
-> eller et dataprodukt-navn (“kortnavn”) - Tredje nivå er datatilstand
- Fjerde nivå er datasett (datafiler)
Støtte for “egendefinerte under-mapper” ved behov for organisering av datasett i flere nivåer
Ved behov er det tillatt å utvide mappestrukturen med med flere egendefinerte nivåer (nivå 4, 5, 6, .., N). Dette kan være nyttig for team som har veldig mange datasett og har behov for å gruppere disse i flere undermapper:
ssb-prod-<team-name>-data-produkt/
└─ <statistikk-kortnavn> | <dataprodukt>_data/
└── <datatilstand>/
└── <egen under-mappe>/
└── <egen under-under-mappe>/
└── <.. osv.>/
├── [datasett-1]
├── [datasett-2]
└── [datasett-NN]- Første nivå er lagringsområdet (bøtte)
- Andre nivå er:
-> enten kortnavn fra Statistikkregisteret
-> eller et dataprodukt-navn (“kortnavn”) - Tredje nivå er datatilstand
- Fjerde nivå er datasett (datafiler)
- Nivå 4, 5, osv. er egendefinerte under-mapper
- Nederste nivå er datasett (datafiler)
Støtte for temporære data (temp-mappe) og oppdragsdata (oppdrag-mappe)
Ved behov for lagring av temporære data (tilsvarende wk-katalogene på Linux på bakken) er det støtte for å opprette en temp -mappe. Temporære data er kun tillatt i data-produkt-bøtten, bør fjernes etter en viss tid, og skal ikke deles med andre (kun tilgjengelige innenfor eget team).
Det er også anbefalt å opprette en oppdrag -mappe for team som jobber med oppdragsvirksomhet. Egne regler gjelder for behandling og oppbevaring av oppdragsdata. Det er derfor ønskelig at disse organiseres i en egen mappe. Utover dette er det anbefalt å ha med WebSak-saksnummer til oppdraget enten som en undermappe eller som en del av datasett-navnet.
ssb-prod-<team-name>-data-produkt/
└─ <statistikk-kortnavn> | <dataprodukt>_data/
└── <datatilstand>/
└── <datatilstand>/
├── [datasett-1]
├── [datasett-2]
└── [datasett-NN]
└─ temp/
├── [temp-datasett-A]
└── [temp-datasett-X]
└─ oppdrag/
└── <WebSak-saksnummer>/
├── [oppdrag-datasett-Y]
└── [oppdrag-datasett-Z]- Første nivå er lagringsområdet (bøtte)
- Andre nivå er:
-> enten kortnavn fra Statistikkregisteret
-> eller et dataprodukt-navn (“kortnavn”) - Tredje nivå er datatilstand
- Fjerde nivå er datasett (datafiler)
Her vises også:
- temp-mappe for temporære data
- oppdrag-mappe for oppdragsdata
Eksempel på mappestruktur i data-produkt-bøtte
Eksempel “Team overnaturlig”
Nedenfor vises et eksempel på hvordan et tenkt team “ Team overnaturlig ” kan organisere sine tenkte statistikkprodukter “ufo” og “superhelt” i en mappestruktur:
ssb-prod-team-overnaturlig-data-produkt/
└── ufo/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└── superhelt/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└── temp/
└── oppdrag/ Eksempel “Team reiseliv” - Seksjon for næringslivets konjunkturer (S422)
Teamet har ansvar for 3 statistikk-produkter (kortnavn “overnatting”, “reise” og “grensehandel”)
- Ett ALTINN-skjema og 2 utvalgsinnsamlinger med intervjuer på telefon/CATI
- Produksjonsløpet har fokus på statistikkprodukter fra kildedata til utdata
ssb-prod-reiseliv-data-produkt/
└── overnatting/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└── reise/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└── grensehandel/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└── temp/Eksempel “Team trygd” - Seksjon for inntekts- og levekårsstatistikk (S350)
Teamet har datainnsamling fra flere av NAV sine register
- Data klargjøres og brukes til flere formål, bl.a. utlån av data til forskere (FD-Trygd) og levering til microdata.no (S380)
Team trygd klargjør dataprodukter, ikke statistikkprodukter. Alle dataprodukt-kortnavn har derfor endelsen “_data” i eksempel-mappestrukturen nedenfor.
ssb-prod-trygd-data-produkt/
└── barnetrygd_data/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└── foedsykp_data/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└── pensj_data/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└──` … osv.
└── temp/
└── oppdrag/